
The history of optimal control - Part I
Published:
Điều Khiển Tối Ưu: Những dấu mốc trên con đường đã qua
Phần 1: Thời Hiện Đại (1950s - nay)
Nhân dịp chuẩn bị tài liệu cho một seminar về optimal control ứng dụng trong autonomous robotic vehicles, xin chia sẻ cùng mọi người một chút hiểu biết mang tính lịch sử, hy vọng thú vị và hữu ích cho ai muốn tham khảo một góc nhìn tổng quan về topic này.
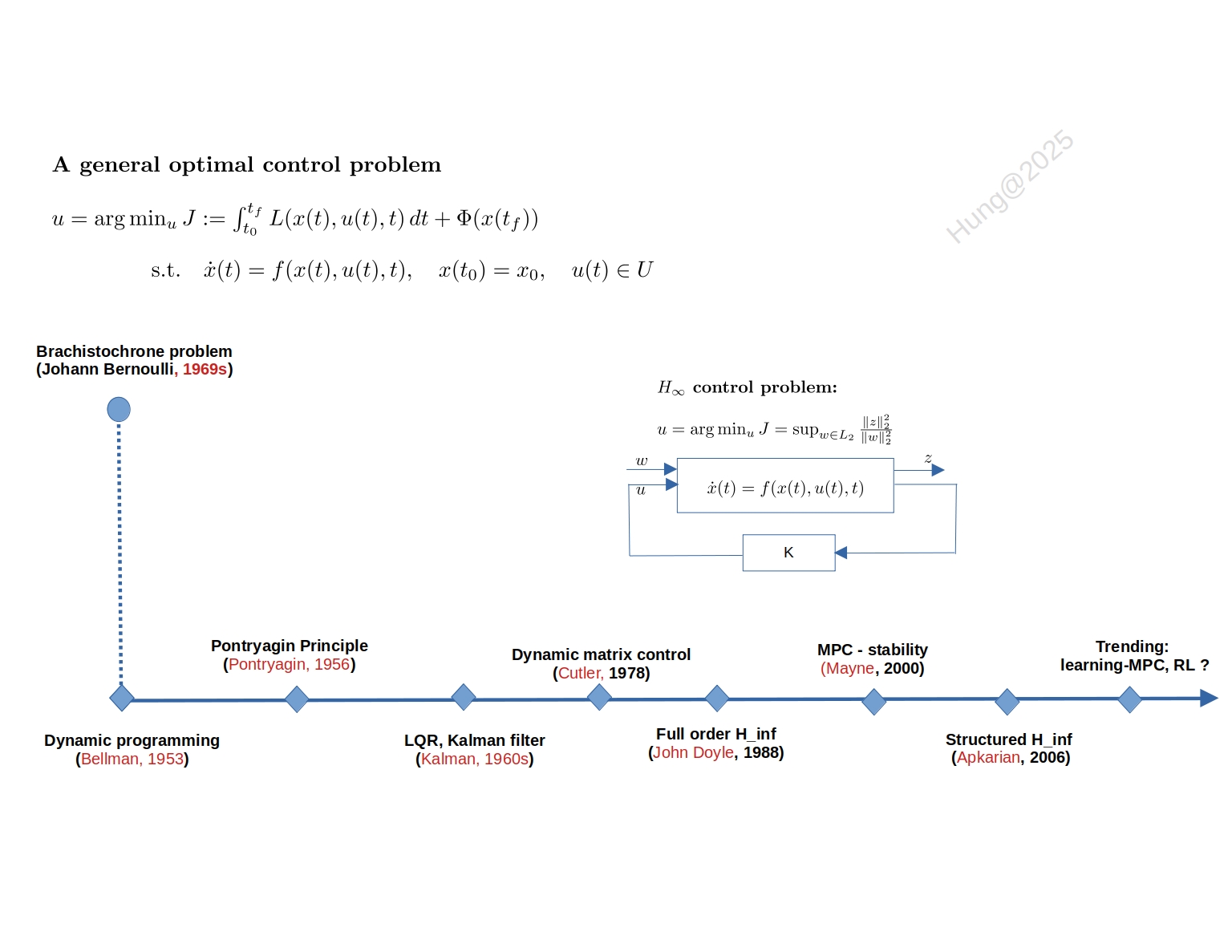
Những người quan tâm đến lịch sử ngành điều khiển có lẽ đều đồng ý rằng optimal control ra đời vào thập niên 1950, thúc đẩy mạnh mẻ một phần bởi cuộc cạnh tranh giữa hai ông lớn Liên Xô và Mỹ sau Thế Chiến thứ hai. Vào thời đó, các bài toán điều khiển tối ưu trong lĩnh vực quân sự được xem là “hot”, bao gồm điều khiển tên lửa, tối ưu hóa vận tải, tối ưu quản lý vật tư, hay tối ưu điều phối lực lượng, vv. Chẳng hạn, với tên lửa, câu hỏi đặt ra là: làm sao để điều khiển nó tiết kiệm nhiên liệu nhất, đi được xa nhất, hay đạt được vận tốc cuối (terminal velocity) lớn nhất.
Phía Mỹ: Bellman giới thiệu Dynamic Programming (DP) vào năm 1953. DP dựa trên Nguyên lý Tối ưu (Principle of Optimality), chia nhỏ bài toán tối ưu tổng thể phức tạp thành các bài toán con để giải quyết. Trong khi đó phía Liên Xô: Pontryagin phát triển Nguyên lý Cực đại (Pontryagin’s Maximum Principle - PMP), công bố vào năm 1957. PMP xây dựng trên nền tảng phương pháp biến phân (Calculus of Variations), cung cấp điều kiện cần cho bài toán điều khiển tối ưu, có thể áp dụng không chỉ cho hệ phi tuyến mà còn ràng buộc ở ngõ vào của hệ thống điều khiển. Thú vị là Pontryagin làm việc trong điều kiện bị mù từ năm 14 tuổi, nên cũng không hiểu là cụ nghiên cứu bằng cách nào mà ra lý thuyết hay thế. Nhưng chắc chắn do bị mù cụ sẽ tập trung hơn vì không thấy được nhiều cám dỗ như anh em chúng ta 😃.
Cả DP và PMP đều đưa ra các điều kiện tối ưu cho một bài toán điều khiển tối ưu tổng quát. Tuy nhiên, hạn chế lớn lúc bấy giờ là không phải lúc nào cũng tìm được luật điều khiển giải tích (analytical control law). Với DP, vấn đề còn nằm ở “lời nguyền chiều (curse of dimensionality)”, trong khi PMP đòi hỏi giải hệ phương trình vi phân biên phức tạp. Thời đó, máy tính còn yếu, và solver/software và các phương pháp số chưa phát triển, nên việc triển khai thực tiễn gặp nhiều khó khăn. Do đó mấy nhà điều khiển học mới nghĩ lại thay vì cố gắng giải bài toán điều khiển tối ưu tổng quát thì liệu xem xét lại các hệ thống đơn giản như tuyến tính, không ràng buộc ở input hay state thì liệu có thể dễ giải hơn không ?
Thập niên 1960 đánh dấu một bước tiến lớn trong điều khiển tối ưu với sự ra đời của Linear Quadratic Regulator (LQR) do Kalman giới thiệu vào năm 1960 [1]. LQR giải quyết bài toán điều khiển tối ưu cho hệ tuyến tính, quadratic cost, không có ràng buộc trên inputs và states. Nhờ đó, dựa trên phương trình Hamilton-Jacobi (HJ), Kalman xây dựng được luật điều khiển tối ưu dưới dạng phản hồi tuyến tính: u=−Kx, với K có thể tính được từ nghiệm của phương trình Riccati. Cũng trong năm 1960, Kalman công bố bộ lọc Kalman [2], mà chắc ai trong chúng ta cũng đã từng thiết kế để ước lượng trạng thái của hệ thống (state estimation). Sự kết hợp giữa LQR và Bộ lọc Kalman tạo nên Linear Quadratic Gaussian (LQG) tạo nên công cụ mạnh mẽ cho điều khiển và ước lượng trạng thái, do dễ thực thi, và ngay lập tức ứng dụng nhiều trong aerospace industry.
Tuy nhiên LQG gặp vấn đề với model uncertainty (eg. parameter uncertainty, model structure uncertainty hay disturbance không phải Gaussian). Để chứng minh điều này năm 1978, John Doyle công bố một bài báo với phần tóm tắt chỉ vỏn vẹn một từ “None” [4], chỉ ra rằng LQG không đảm bảo biên độ ổn định (gain and phase margin), tức là có những hệ thống chỉ cần có chút khác biệt giữa mô hình thiết kế LQG và hệ thống thực thì khi triển khai hệ thống có thể mất ổn định. Phát hiện này đặt ra vấn đề đau đầu cho các nhà làm điều khiển, mở ra một hướng nghiên cứu mới gọi là robust control, kéo dài cho đến thập niên 90s. George Zames được xem là người tiên phong trong robust control, xây dựng bài toán H_inf, đâu đó từ năm 1981. H_inf khác với LQR ở chỗ trong khi LQR tập trung tối ưu hóa performance (ví dụ minimize tracking error hay input expense), thì H_inf tập trung giảm thiểu tối đa ảnh hưởng của exogenous disturbance input (ví dụ như nhiễu của actuator, của sensor …) lên performance (mọi người có thể xem hình để hình dung rõ hơn). Tuy nhiên mãi đến năm 1988, lại là John Doyle người chỉ ra bất cập LQR công bố giải pháp mang tính đột phá [5] cho bài toán H_inf. Phương pháp của John Doyle dựa trên mô hình trạng thái state-space nên tổng quát và sau này được tích hợp trong Robust Control Toolbox của MATLAB. Robust Control Toolbox còn tích hợp một solution khác cho H_inf dùng phương pháp LMI, phát triển nhiều năm sau đó bởi Pierre Apkarian [7], 1994.
Bộ điều khiển H∞ của Doyle có dạng một state-space model có bậc bằng tổng bậc của hệ thống được điều khiển và bậc của các trọng số thêm vào trong quá trình thiết kế nên thường là có bậc cao. Vì tính chất này nó còn được gọi là full-order H_inf. Một số tài liệu khác bộ điều khiển H_inf này còn được gọi unstructured H_inf vì mình không biết cấu trúc bên trong bộ điều khiển là như thế nào cả. Hai điều này không phải tốt lắm trong thực tế vì nếu bộ điều khiển có bậc cao sẽ làm tăng thời gian tính toán và vì nó không có cấu trúc nên rất khó tunning. Do đó bài toán mới đặt ra cho H_inf là liệu có thể thiết kế một bộ điều khiển đơn giản, có cấu trúc rõ ràng như PID mà vẫn đảm bảo robust được hay không ?
Pierre Apkarian và cộng sự theo đuổi bài toán này và đến năm 2017 tóm tắt trong một bài báo có tên rất kêu “The H∞ Control Problem is Solved” [6]. Ý tưởng của Pierre là fix cấu trúc của bộ điều khiển trước, ví dụ như PID chẳng hạn rồi tìm giải pháp để tune các hệ số của bộ điều khiển (Kp, Ki..) sau, sao cho nó vẫn robust. Ý tưởng thì đơn giản nhưng bản chất bài toán H_inf này lại khó hơn nhiều vì bộ điều khiển bị ràng buộc về cấu trúc, mà ai đã từng làm về tối ưu đều biết, càng nhiều ràng buộc bài toán tối ưu càng càng khó giải, thậm chí không khả thi. Để giải bài toán này, Pierre dùng công cụ non-smooth optimization và đưa ra phiên bản đầu tiên tích hợp vào Matlatlab đâu đó vào năm 2011. Bản thân mình cũng từng dùng các công cụ này để thiết kế bộ điều khiển cho satellites hay launching vehicles, tuy nhiên để dùng tốt cũng mất khá nhiều thời gian vì đòi kiến thức của người thiết kế phải thực sự hiểu sâu về hệ thống và biết phân tích, thiết kế hệ thống điều khiển trong miền tần số.
Ngày nay, một trong những kỷ thuật quan trọng bậc nhất liên quan đến điều khiển tối ưu là Model Predictive Control (MPC). MPC cơ bản là phương pháp điều khiển mà ở đó: giải bài toán tối ưu trong một khoảng thời gian hữu hạn (finite horizon), apply optimal control cho bước tiếp theo, rồi lặp lại quá trình này tại mỗi thời điểm lấy mẫu. Lịch sử của MPC cũng trải qua nhiều phiên bản nhưng phiên bản đầu tiên được xem phát triển bởi công ty Shell Oil, gọi là Dynamic matrix control (DMC), từ những năm 1970s [8]. DMC sử dụng mô hình step response, phổ biến trong process control để dự báo response của process và tìm chuỗi điều khiển tối ưu để miminize tracking error. Sau DMC, Mỗi phương pháp MPC khác dùng những mô hình khác nhau như Generalized Predictive Control dùng CARIMA, hay Transfer Function, vv. Bây giờ state-space dường như trở thành mô hình chuẩn để mô hình hóa hệ thống khi thiết kế MPC, nên các version trước dường như không ai nhắc đến nữa.
Về mặt lý thuyết, dù MPC xuất hiện từ 1970s, phải đến năm 2000, bài báo nổi tiếng của D.Q. Mayne và cộng sự [3] mới giải thích đầy đủ tại sao MPC worked, làm rõ stability, performance, and feasibility của MPC. Mayne tổng kết các phiên bản MPC và đưa ra điều kiện thiết kế cho terminal cost và terminal constraint để vừa đảm bảo recursive feasibility cho bài toán tối ưu trong MPC đồng thời stability.
Trong thực tiễn, vấn đề lớn nhất của MPC là yêu cầu tính toán để giải bài toán tối ưu tại mỗi bước, vì thế ban đầu chỉ phù hợp với hệ thống chậm trong process control như hóa dầu. Ngày nay nhờ tiến bộ phần cứng và phần mềm (solvers), MPC ngày nay áp dụng rộng rãi trong hệ thống nhanh như xe hơi và robotic vehicles, mở rộng sang path/trajectory planning và cả state estimation (e.g., Moving Horizon Estimation). Từ thập niên 2000, MPC phát triển mạnh mẽ với các nhánh như robust MPC, stochastic MPC, distributed MPC, và gần đây là learning-based MPC, để giải quyết các vấn đề phức tạp hơn của hệ thống như model uncertainty, …vv.
Cuối cùng nói về điều khiển tối ưu chắc cần nhắc đến Reinforcement Learning (RL) dù nó xuất thân từ AI community. Có câu hỏi là RL có phải là một phương pháp điều khiển tối ưu không? Mình cho là có vì bản chất RL tìm kiếm chính sách (policy/control law) cho ngỏ vào input để maximize hàm thưởng (reward function), rất giống với concept với điều khiển tối ưu. Sâu hơn có thể chỉ ra tương quan giữa RL và optimal control (ví dụ như, Bellman Equation trong RL giống HJB trong control), nhưng mình chưa đủ trãi nghiệm với RL để phân tích sâu hơn nên xin dành lại bình luận cho những ai làm sâu về RL chia sẻ thêm trong lĩnh vực này.
Như vậy, có thể thấy lịch sử optimal control có một hành trình thú vị gần một thế kỷ qua. Thú vị hơn ngày càng thấy sự giao thoa của nó với các lĩnh vực khác vị dụ RL nguồn gốc từ AI. Nhờ sự tiến bộ vượt bậc của máy tính và phần mềm trong đó phải kể đến các solver software, việc ứng dụng optimal control (đặc biệt MPC) ngày càng dễ dàng hơn trong các hệ thống thực tế. Tuy nhiên ngày nay, khi sử dụng solver để giải các bài toán tối ưu mọi người có thể rất dễ quên một lịch sử đẹp thú vị của optimal control từ những ngày 1950s đến nay và thậm chí trước đó nữa.
Và để những lịch sử thú vị đó không bị lãng quên mình sẽ kể nó vào Phần 2 của topic này trong những ngày tiếp theo, mang tên “Những ngày trước 1950s.”
- [1] Kalman, R.E. (1960). Contributions to the Theory of Optimal Control.
- [2] Kalman, R.E. (1960). A New Approach to Linear Filtering and Prediction Problems.
- [3] Mayne, D.Q., et al. (2000). Constrained Model Predictive Control: Stability and Optimality, Automatica.
- [4] Doyle, J.C. (1978). Guaranteed Margins for LQG Regulators.
- [5] Doyle, J.C., et al. (1988). State-Space Solutions to Standard H2 and H∞ Control Problems.
- [6] Apkarian, P., et al. (2017). The H∞ Control Problem is Solved.
- [7] Apkarian (1994) A linear matrix inequality approach to H∞ control
- [8] C.R. Cutler (1980), Dynamix Matrix Control